
Stream Data into Hadoop using Flume
We all know that Sqoop is a component used to transfer structured data from RDBMS like databases (e.g. MySQL, SQL Server, ect.) to Hadoop HDFS and vice versa (from HDFS to RDBMS). Now, what if we want to load semi-structured and unstructured data into Hadoop HDFS, or live streaming data that is generated from sources like twitter, facebook, weblogs and more into Hadoop HDFS.
Solution (Proposition)
The solution to the challenge in the Hadoop ecosystem is Flume, which is a component used to collect, aggregate and moves large amount of log data from different sources to a centralized data store. It is an open source component which is designed to locate and store the data in a distributed environment and collects the data as per the specified input key(s).
Following are other features that Flume can provides:
- Data can be fetched in parallel
- Also it can be directly stored into distributed file systems (one step)
- If we want to load data into Hive or HBase, no need to write different programs and need to maintain them
- … etc.
Prerequisites
- Hadoop
- Flume
- Streaming data source
Solution Architecture
Before moving forward and deploy the data pipeline using Flume, It is mandatory to know its architecture. In this project, we used Flume to collect data from the Twitter Streaming API and forward it to HDFS. Looking closer at the Flume pipeline from that example, we come away with a system like this:
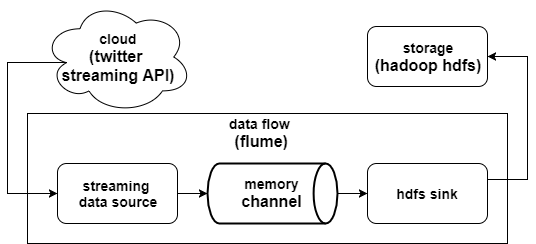
Flume data flow is composed of the following components:
source: it’s the component that connects to a source and receives data from data generators (twitter, facebook, weblogs, etc.), then transfers the data to one or more channels in the form of Flume event. Sources operate by gathering discrete pieces of data, translating the data into individual events, and then using the channel to process events one at a time, or as a batch.flume Agent: it’s an independent JVM daemon process that receives the data (events) from clients and transport them to the subsequent destination (sink or agent).channel:channels act as a pathway between the sources and sinks. Events are added to channels by sources, and later removed from the channels by sinks. Flume dataflows can actually support multiple channels, which enables more complicated dataflows.sink:Sinks take events and send them to a resting location or forward them on to another agent. In our case, we are using HDFS sink that writes events to a configured location in HDFS.
Deployment
Data Source
For this project, streaming twitter data is used as our data source. In order to get the twitter feed working you need the following four keys that you can get them after walking through these simple steps:
- Consumer Key (API Key)
- Consumer Secret (API Secret)
- Access Token
- Access Token Secret
Twitter JARs
Make sure you have below jars in your $FLUME_HOME/lib directory, otherwise download them:
- twitter4j-core-X.XX.jar
- twitter4j-stream-X.X.X.jar
- twitter4j-media-support-X.X.X.jar
Stream Data into HDFS
Now, we’ll take an in-depth look at the pieces of Flume that are used to build dataflows, and specifically how they were used.
Step 1
As a first step, create a new file inside the $FLUME_HOME/lib and name it twitter.conf. Open the file and add the below configurations step by step:
1) Configuring the Source
To understand how sources operate more thoroughly, let’s look at how the twitter source was built:
# Describing/Configuring the source
TwitterAgent.sources.Twitter.type = org.apache.flume.source.twitter.TwitterSource
TwitterAgent.sources.Twitter.consumerKey=bVd3fwceBGCvjghPqjVF6A2jW
TwitterAgent.sources.Twitter.consumerSecret=86EPCj7ByjPpPTx4vNN1nTYqOsdjN0v7ZsainjEgjGY6KzwjFV
TwitterAgent.sources.Twitter.accessToken=559516596-yDA9xqOljo4CV32wSnqsx2BXh4RBIRKFxZGSZrPC
TwitterAgent.sources.Twitter.accessTokenSecret=zDxePILZitS5tIWBhre0GWqps0FIj9OadX8RZb6w8ZCwz
TwitterAgent.sources.Twitter.keywords= hadoop, spark, big data, science, analytics
type: source type, in our project is twitterconsumerKey: consumer key (refer to the twitter app to get this)consumerSecret: consumer secret (refer to the twitter app to get this)accessToken: consumer token (refer to the twitter app to get this)accessTokenSecret: access token secret (refer to the twitter app to get this)keywords: keywords to be collected from the twitter application. In our case, we are fetching tweet data related to hadoop, spark, big data, science, analytics
With this code, we have a configurable source that we can plug into Flume, although at this stage, it won’t do anything.
2) Channels
For this project, we’ve defined a memory channel as follows:
# Describing/Configuring the channel
TwitterAgent.channels.MemChannel.type=memory
TwitterAgent.channels.MemChannel.capacity=10000
TwitterAgent.channels.MemChannel.transactionCapacity=1000
Memory channels use an in-memory queue to store events until they’re ready to be written to a sink. Memory channels are useful for dataflows that have a high throughput. however, since events are stored in memory in the channel they may be lost if the agent experiences a failure. If the risk of data loss is not tolerable, this situation can be remedied using a different type of channel.
4) Sinks
The final piece of the Flume dataflow is the sink:
# Describing/Configuring the sink
TwitterAgent.sinks.HDFS.channel=MemChannel
TwitterAgent.sinks.HDFS.type=hdfs
TwitterAgent.sinks.HDFS.hdfs.useLocalTimeStamp = true
TwitterAgent.sinks.HDFS.hdfs.path=hdfs://localhost:9000/tmp/data_staging/tweets/%y-%m-%d-%h
TwitterAgent.sinks.HDFS.hdfs.fileType=DataStream
TwitterAgent.sinks.HDFS.hdfs.writeformat=Text
TwitterAgent.sinks.HDFS.hdfs.batchSize=1000
TwitterAgent.sinks.HDFS.hdfs.rollSize=0
TwitterAgent.sinks.HDFS.hdfs.rollCount=10000
TwitterAgent.sinks.HDFS.hdfs.rollInterval=600
The HDFS sink configuration we used does a number of things with the following elements:
rollCount: it defines the size of the files with the parameter, so each file will be containing 10,000 tweetsfileType: this retains the original data format, by setting it to DataStream and settingwriteFormatto Text. This is done instead of storing the data as a SequenceFile or some other format.- The most interesting piece, however, is the file path. The file path, as defined, uses some wildcards to specify that the files will end up in directories where the year, month, day and hour during which the events occur is mentioned as their name. For example, an event that comes in at 1/28/2017 6:00AM will end up in HDFS at hdfs://localhost:9000/tmp/data_staging/tweets/2017-01-28-06.
Finally, here is the whole configuration:
TwitterAgent.sources = Twitter
TwitterAgent.channels = MemChannel
TwitterAgent.sinks = HDFS
# Describing/Configuring the source
TwitterAgent.sources.Twitter.type = org.apache.flume.source.twitter.TwitterSource
TwitterAgent.sources.Twitter.consumerKey=lH8zRXkZ2xMf8VgFO9UL2dMb2
TwitterAgent.sources.Twitter.consumerSecret=ANL1Aat6JYhGs7GPvch6PoCU9SRkLA3CGnRjwhNhYjR1hUcqGZ
TwitterAgent.sources.Twitter.accessToken=2974223241-5A06T1hlLIrBF2AMGgyqcM4jHR9ZqW2jzqM1mFE
TwitterAgent.sources.Twitter.accessTokenSecret=Lbwg4RnkDO26AdikpBTaQvRNy2WAIGyo5R68ZHqCUUXhx
TwitterAgent.sources.Twitter.keywords= hadoop, spark, big data, science, analytics
# Describing/Configuring the sink
TwitterAgent.sinks.HDFS.channel=MemChannel
TwitterAgent.sinks.HDFS.type=hdfs
# TwitterAgent.sinks.HDFS.hdfs.path=hdfs://localhost:9000/tmp/data_staging/tweets
TwitterAgent.sinks.HDFS.hdfs.useLocalTimeStamp = true
TwitterAgent.sinks.HDFS.hdfs.path=hdfs://localhost:9000/tmp/data_staging/tweets/%y-%m-%d
TwitterAgent.sinks.HDFS.hdfs.fileType=DataStream
TwitterAgent.sinks.HDFS.hdfs.writeformat=Text
TwitterAgent.sinks.HDFS.hdfs.batchSize=1000
TwitterAgent.sinks.HDFS.hdfs.rollSize=0
TwitterAgent.sinks.HDFS.hdfs.rollCount=10000
TwitterAgent.sinks.HDFS.hdfs.rollInterval=600
# Describing/Configuring the channel
TwitterAgent.channels.MemChannel.type=memory
TwitterAgent.channels.MemChannel.capacity=10000
TwitterAgent.channels.MemChannel.transactionCapacity=1000
# Binding the source and sink to the channel
TwitterAgent.sources.Twitter.channels = MemChannel
TwitterAgent.sinks.HDFS.channel = MemChannel
Step 2:
Now it’s time give the thing a shot. So before running flume to start fetching data, make sure that all Hadoop daemons are running. Use jps command:
$ jps
8686 DataNode
9193 ResourceManager
770 JobHistoryServer
8960 SecondaryNameNode
8524 NameNode
8271 Worker
8126 Master
28159 Jps
9526 NodeManager
Create a new directory inside HDFS path, where the data should be stored
$ hadoop dfs -mkdir /tmp/data_staging/tweets
After making sure that Hadoop daemons are up and the storage directory is created, we need to start up the agent to get the dataflow running. Before we actually start the agent, we need to set the agent to have the appropriate name as defined in the configuration.
The flume-ng agent contains one environment variable defined called FLUME_AGENT_NAME. In a production system, for simplicity, the FLUME_AGENT_NAME will typically be set to the hostname of the machine on which the agent is running. However, in this case, we set it to TwitterAgent, and we’re ready to start up the process.
$ flume-ng agent -n TwitterAgent -f path/to/twitter.conf
Then, the tweet data will start streaming into HDFS. Once you you have got enough data, you can stop the whole thing using Ctrl + c. To check the content of the tweet data we can use the following command:
hadoop dfs -cat /tmp/data_staging/tweets/*/*
Boom we have successfully fetched twitter data into our HDFS, as a next step you can start manipulate the data to achieve you analytics objectives such as sentiment and context analysis to measure customers feeling against products and services, and detect which areas needs urgent improvements or more personalizations.
End notes
In this article, you’ve seen how to develop a custom source and process events from Twitter. The same approach can be used to build custom sources for other types of data. Also, we’ve looked at how to configure a basic, complete dataflow for Flume, to bring data into HDFS as it is generated. A distributed filesystem isn’t particularly useful unless you can get data into it, and Flume provides an efficient, reliable way to achieve just that.