
Querying Semi-Unstructured Data using Hive
There are five types of data structures
- Well structured for example online purchase transactions. Generally can be stored in RDBMS in the form of rows and columns
- Incompatibly structured such as data in Avro, JSON files, XML
- Semi-structured like clickstream in log files (
2017-01-29 14:27:57,944-INFO : com.ovaledge.oasis.dao.DomainDaoImpl), where we see the structure but require some rules to find the details - Unstructured text data text written in various forms such as web pages, emails, chat messages, pdf files, word documents, etc.
- Fully unstructured like videos, audio files and pictures
Looking at all the above types that the data can have, the first question that comes to mind when deciding on the right tool for the job is: “How is the data look like?”. If your data has a very strict schema, and it doesn’t deviate from that schema, then it’s just well structured data. Then, maybe you should just be using an RDBMS like MySQL. However, as you start to try to analyze data with less structure or with extremely high volume, systems like MySQL become less useful, and it may become necessary to move out of the relational world.
Solution (Proposition)
Incompatibly structured, semi-structured, unstructured text data and fully unstructured are all terms for data that doesn’t fit well or it doesn’t at all into the relational model / RDBMS. What do we do with this data? Here’s where Hive shines. it’s a data warehouse software project built on top of Apache Hadoop for providing data summarization, query and analysis. Hive gives a SQL-like interface to query data stored in various databases and file systems that integrate with Hadoop.
It’s extremely effective for dealing with data that doesn’t quite fit into the RDBMS bucket, because it can process complex, nested types natively. Hive avoids the need for complicated transformations that might be otherwise necessary to handle this sort of data in a traditional relational system. Hive can also gracefully handle records that don’t strictly conform to a table’s schema. For example, if some columns are missing from a particular record, Hive can deal with the record by treating missing columns as NULLs.
Prerequisites
- Hadoop HDFS / HBase
- Hive
- Datasets (tweet data)
Solution Architecture (Data Pipeline)
Before moving forward and deploy the data pipeline using big data tools including Hive, It is mandatory to know its architecture:
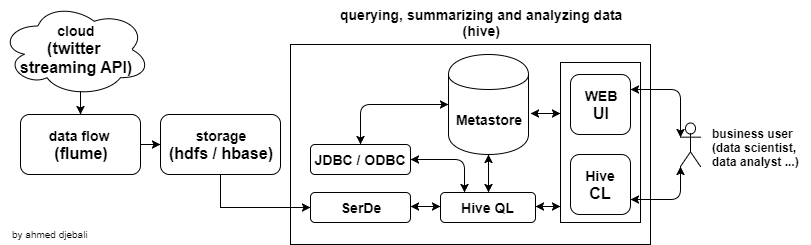
Data Source
For this project, we are going to summarize, query and analyze twitter data. And as we already talked on how to stream twitter data into Hadoop HDFS, then that last is our data source.
Data Structure (tweet data)
Using the Twitter Streaming API, we loaded raw tweets into HDFS using Flume. tweets are represented as JSON blobs.
{
"statuses": [
{
"coordinates": null,
"favorited": false,
"truncated": false,
"created_at": "Mon Sep 24 03:35:21 +0000 2012",
"id_str": "250075927172759552",
"entities": {
"urls": [
],
"hashtags": [
{
"text": "freebandnames",
"indices": [
20,
34
]
}
],
"user_mentions": [
]
},
"in_reply_to_user_id_str": null,
"contributors": null,
"text": "Aggressive Ponytail #freebandnames",
"metadata": {
"iso_language_code": "en",
"result_type": "recent"
},
"retweet_count": 0,
"in_reply_to_status_id_str": null,
"id": 250075927172759552,
"geo": null,
"retweeted": false,
"in_reply_to_user_id": null,
"place": null,
"user": {
"profile_sidebar_fill_color": "DDEEF6",
"profile_sidebar_border_color": "C0DEED",
"profile_background_tile": false,
"name": "Sean Cummings",
"profile_image_url": "http://a0.twimg.com/profile_images/2359746665/1v6zfgqo8g0d3mk7ii5s_normal.jpeg",
"created_at": "Mon Apr 26 06:01:55 +0000 2010",
"location": "LA, CA",
"follow_request_sent": null,
"profile_link_color": "0084B4",
"is_translator": false,
"id_str": "137238150",
"entities": {
"url": {
"urls": [
{
"expanded_url": null,
"url": "",
"indices": [
0,
0
]
}
]
},
"description": {
"urls": [
]
}
},
"default_profile": true,
"contributors_enabled": false,
"favourites_count": 0,
"url": null,
"profile_image_url_https": "https://si0.twimg.com/profile_images/2359746665/1v6zfgqo8g0d3mk7ii5s_normal.jpeg",
"utc_offset": -28800,
"id": 137238150,
"profile_use_background_image": true,
"listed_count": 2,
"profile_text_color": "333333",
"lang": "en",
"followers_count": 70,
"protected": false,
"notifications": null,
"profile_background_image_url_https": "https://si0.twimg.com/images/themes/theme1/bg.png",
"profile_background_color": "C0DEED",
"verified": false,
"geo_enabled": true,
"time_zone": "Pacific Time (US & Canada)",
"description": "Born 330 Live 310",
"default_profile_image": false,
"profile_background_image_url": "http://a0.twimg.com/images/themes/theme1/bg.png",
"statuses_count": 579,
"friends_count": 110,
"following": null,
"show_all_inline_media": false,
"screen_name": "sean_cummings"
},
"in_reply_to_screen_name": null,
"source": "Twitter for Mac",
"in_reply_to_status_id": null
},
{
"coordinates": null,
"favorited": false,
"truncated": false,
"created_at": "Fri Sep 21 23:40:54 +0000 2012",
"id_str": "249292149810667520",
"entities": {
"urls": [
],
"hashtags": [
{
"text": "FreeBandNames",
"indices": [
20,
34
]
}
],
"user_mentions": [
]
},
"in_reply_to_user_id_str": null,
"contributors": null,
"text": "Thee Namaste Nerdz. #FreeBandNames",
"metadata": {
"iso_language_code": "pl",
"result_type": "recent"
},
"retweet_count": 0,
"in_reply_to_status_id_str": null,
"id": 249292149810667520,
"geo": null,
"retweeted": false,
"in_reply_to_user_id": null,
"place": null,
"user": {
"profile_sidebar_fill_color": "DDFFCC",
"profile_sidebar_border_color": "BDDCAD",
"profile_background_tile": true,
"name": "Chaz Martenstein",
"profile_image_url": "http://a0.twimg.com/profile_images/447958234/Lichtenstein_normal.jpg",
"created_at": "Tue Apr 07 19:05:07 +0000 2009",
"location": "Durham, NC",
"follow_request_sent": null,
"profile_link_color": "0084B4",
"is_translator": false,
"id_str": "29516238",
"entities": {
"url": {
"urls": [
{
"expanded_url": null,
"url": "http://bullcityrecords.com/wnng/",
"indices": [
0,
32
]
}
]
},
"description": {
"urls": [
]
}
},
"default_profile": false,
"contributors_enabled": false,
"favourites_count": 8,
"url": "http://bullcityrecords.com/wnng/",
"profile_image_url_https": "https://si0.twimg.com/profile_images/447958234/Lichtenstein_normal.jpg",
"utc_offset": -18000,
"id": 29516238,
"profile_use_background_image": true,
"listed_count": 118,
"profile_text_color": "333333",
"lang": "en",
"followers_count": 2052,
"protected": false,
"notifications": null,
"profile_background_image_url_https": "https://si0.twimg.com/profile_background_images/9423277/background_tile.bmp",
"profile_background_color": "9AE4E8",
"verified": false,
"geo_enabled": false,
"time_zone": "Eastern Time (US & Canada)",
"description": "You will come to Durham, North Carolina. I will sell you some records then, here in Durham, North Carolina. Fun will happen.",
"default_profile_image": false,
"profile_background_image_url": "http://a0.twimg.com/profile_background_images/9423277/background_tile.bmp",
"statuses_count": 7579,
"friends_count": 348,
"following": null,
"show_all_inline_media": true,
"screen_name": "bullcityrecords"
},
"in_reply_to_screen_name": null,
"source": "web",
"in_reply_to_status_id": null
},
{
"coordinates": null,
"favorited": false,
"truncated": false,
"created_at": "Fri Sep 21 23:30:20 +0000 2012",
"id_str": "249289491129438208",
"entities": {
"urls": [
],
"hashtags": [
{
"text": "freebandnames",
"indices": [
29,
43
]
}
],
"user_mentions": [
]
},
"in_reply_to_user_id_str": null,
"contributors": null,
"text": "Mexican Heaven, Mexican Hell #freebandnames",
"metadata": {
"iso_language_code": "en",
"result_type": "recent"
},
"retweet_count": 0,
"in_reply_to_status_id_str": null,
"id": 249289491129438208,
"geo": null,
"retweeted": false,
"in_reply_to_user_id": null,
"place": null,
"user": {
"profile_sidebar_fill_color": "99CC33",
"profile_sidebar_border_color": "829D5E",
"profile_background_tile": false,
"name": "Thomas John Wakeman",
"profile_image_url": "http://a0.twimg.com/profile_images/2219333930/Froggystyle_normal.png",
"created_at": "Tue Sep 01 21:21:35 +0000 2009",
"location": "Kingston New York",
"follow_request_sent": null,
"profile_link_color": "D02B55",
"is_translator": false,
"id_str": "70789458",
"entities": {
"url": {
"urls": [
{
"expanded_url": null,
"url": "",
"indices": [
0,
0
]
}
]
},
"description": {
"urls": [
]
}
},
"default_profile": false,
"contributors_enabled": false,
"favourites_count": 19,
"url": null,
"profile_image_url_https": "https://si0.twimg.com/profile_images/2219333930/Froggystyle_normal.png",
"utc_offset": -18000,
"id": 70789458,
"profile_use_background_image": true,
"listed_count": 1,
"profile_text_color": "3E4415",
"lang": "en",
"followers_count": 63,
"protected": false,
"notifications": null,
"profile_background_image_url_https": "https://si0.twimg.com/images/themes/theme5/bg.gif",
"profile_background_color": "352726",
"verified": false,
"geo_enabled": false,
"time_zone": "Eastern Time (US & Canada)",
"description": "Science Fiction Writer, sort of. Likes Superheroes, Mole People, Alt. Timelines.",
"default_profile_image": false,
"profile_background_image_url": "http://a0.twimg.com/images/themes/theme5/bg.gif",
"statuses_count": 1048,
"friends_count": 63,
"following": null,
"show_all_inline_media": false,
"screen_name": "MonkiesFist"
},
"in_reply_to_screen_name": null,
"source": "web",
"in_reply_to_status_id": null
},
{
"coordinates": null,
"favorited": false,
"truncated": false,
"created_at": "Fri Sep 21 22:51:18 +0000 2012",
"id_str": "249279667666817024",
"entities": {
"urls": [
],
"hashtags": [
{
"text": "freebandnames",
"indices": [
20,
34
]
}
],
"user_mentions": [
]
},
"in_reply_to_user_id_str": null,
"contributors": null,
"text": "The Foolish Mortals #freebandnames",
"metadata": {
"iso_language_code": "en",
"result_type": "recent"
},
"retweet_count": 0,
"in_reply_to_status_id_str": null,
"id": 249279667666817024,
"geo": null,
"retweeted": false,
"in_reply_to_user_id": null,
"place": null,
"user": {
"profile_sidebar_fill_color": "BFAC83",
"profile_sidebar_border_color": "615A44",
"profile_background_tile": true,
"name": "Marty Elmer",
"profile_image_url": "http://a0.twimg.com/profile_images/1629790393/shrinker_2000_trans_normal.png",
"created_at": "Mon May 04 00:05:00 +0000 2009",
"location": "Wisconsin, USA",
"follow_request_sent": null,
"profile_link_color": "3B2A26",
"is_translator": false,
"id_str": "37539828",
"entities": {
"url": {
"urls": [
{
"expanded_url": null,
"url": "http://www.omnitarian.me",
"indices": [
0,
24
]
}
]
},
"description": {
"urls": [
]
}
},
"default_profile": false,
"contributors_enabled": false,
"favourites_count": 647,
"url": "http://www.omnitarian.me",
"profile_image_url_https": "https://si0.twimg.com/profile_images/1629790393/shrinker_2000_trans_normal.png",
"utc_offset": -21600,
"id": 37539828,
"profile_use_background_image": true,
"listed_count": 52,
"profile_text_color": "000000",
"lang": "en",
"followers_count": 608,
"protected": false,
"notifications": null,
"profile_background_image_url_https": "https://si0.twimg.com/profile_background_images/106455659/rect6056-9.png",
"profile_background_color": "EEE3C4",
"verified": false,
"geo_enabled": false,
"time_zone": "Central Time (US & Canada)",
"description": "Cartoonist, Illustrator, and T-Shirt connoisseur",
"default_profile_image": false,
"profile_background_image_url": "http://a0.twimg.com/profile_background_images/106455659/rect6056-9.png",
"statuses_count": 3575,
"friends_count": 249,
"following": null,
"show_all_inline_media": true,
"screen_name": "Omnitarian"
},
"in_reply_to_screen_name": null,
"source": "Twitter for iPhone",
"in_reply_to_status_id": null
}
],
"search_metadata": {
"max_id": 250126199840518145,
"since_id": 24012619984051000,
"refresh_url": "?since_id=250126199840518145&q=%23freebandnames&result_type=mixed&include_entities=1",
"next_results": "?max_id=249279667666817023&q=%23freebandnames&count=4&include_entities=1&result_type=mixed",
"count": 4,
"completed_in": 0.035,
"since_id_str": "24012619984051000",
"query": "%23freebandnames",
"max_id_str": "250126199840518145"
}
}
It’s fairly easy to see that there is a good bit of complexity to this data structure. Since JSON can contain nested data structures, it becomes very hard to force JSON data into a standard relational schema. Processing JSON data in a relational database would likely require significant transformation, making the job much more cumbersome.
Looking at this particular bit of JSON, there are some very interesting fields:
retweeted_statusindicates that this tweet was retweeted by another user. If it wasn’t, you wouldn’t have it.texttweet’s contenturltweet url- … etc,
Tweets also contain an entities element, which is a nested structure. It contains three arrays, the elements of which are all nested structures in their own right, as can be seen in the hashtags array, which has two entries. How do we deal with a record like this in Hive?
Complex Data Structures
Hive supports for a set of data structures that normally would either not exist in a relational database, or would require definition of custom types. There are all the usual players: integers, strings, floats, and the like, but the interesting ones are the more exotic maps, arrays, and structs. Maps and arrays work in a fairly intuitive way, similar to how they work in many scripting languages:
SELECT array_column[0] FROM table_name;
SELECT map_column[‘map_key’] FROM table_name;
Structs are a little more complicated, since they are arbitrary structures, and a struct field can be queried much like an instance variable in a Java class:
SELECT struct_column.struct_field FROM table_name;
To store the data for a tweet, arrays and structs will be crucial.
Hive Table (tweet table)
In order to store tweets, here is some of columns of the Hive table that was designed to achieve this:
CREATE EXTERNAL TABLE tweets
(
...
retweeted_status STRUCT<
text:STRING,
user:STRUCT<screen_name:STRING,name:STRING>>,
entities STRUCT<
urls:ARRAY<STRUCT<expanded_url:STRING>>,
user_mentions:ARRAY<STRUCT<screen_name:STRING,name:STRING>>,
hashtags:ARRAY<STRUCT<text:STRING>>>,
text STRING,
...
);
PARTITIONED BY (datehour INT)
ROW FORMAT SERDE 'com.cloudera.hive.serde.JSONSerDe'
LOCATION '/tmp/data_staging/tweets';
By comparing the JSON objects from the tweet with the columns in the table, we can see how the JSON objects are mapped to Hive columns. Looking at the entities column, we can see what a particularly complex column might look line:
entities STRUCT<
urls:ARRAY<STRUCT<expanded_url:STRING>>,
user_mentions:ARRAY<STRUCT<screen_name:STRING,name:STRING>>,
hashtags:ARRAY<STRUCT<text:STRING>>>,
entities is a struct which contains three arrays, and each individual array stores elements which are also structs. If we wanted to query the screen names of the first mentioned user from each tweet, we could write a query like this:
SELECT entities.user_mentions[0].screen_name FROM tweets;
If the user_mentions array is empty, Hive will just return NULL for that record.
The PARTITIONED BY clause utilizes a feature of Hive called partitioning, which allows tables to be split up in different directories. By building queries that involve the partitioning column, Hive can determine that certain directories cannot possibly contain results for a query. Partitioning allows Hive to skip the processing of entire directories at query time, which can improve query performance dramatically.
The LOCATION clause is a requirement when using EXTERNAL tables. By default, data for tables is stored in a directory located at /user/hive/warehouse/
EXTERNAL tables can specify an alternate location where the table data resides, which works nicely if Flume is being used to place data in a predetermined location. EXTERNAL tables also differ from regular Hive tables, in that the table data will not be removed if the EXTERNAL table is dropped.
The ROW FORMAT clause is the most important one for this table. In simple datasets, the format will likely be DELIMITED, and we can specify the characters that terminate fields and records, if the defaults are not appropriate. However, for the tweets table, we’ve specified a SERDE.
Serializers and Deserializers
In Hive, SerDe is an abbreviation for Serializer and Deserializer, and is an interface used by Hive to determine how to process a record. Serializers and Deserializers operate in opposite ways. The Deserializer interface takes a string or binary representation of a record, and translates it into a Java object that Hive can manipulate. The Serializer, on the other hand, will take a Java object that Hive has been working with, and turn it into something that Hive can write to HDFS. Commonly, Deserializers are used at query time to execute SELECT statements, and Serializers are used when writing data, such as through an INSERT-SELECT statement. In this project, we wrote a JSONSerDe, which can be used to transform a JSON record into something that Hive can process.
Before moving forward, make sure json-serde-X.X.X.jar is in your $HIVE_HOME/lib directory, otherwise download it.
Deployment (Putting all together)
So far, you have seen the steps on how to transform semi-structured data (JSON) into a structured Hive table. So let’s put them all together.
Create a file containing HiveQL statements as follows:
$ nano tweet.hql
Copy paste these HiveQL statements into the file we have just created:
set hive.exec.dynamic.partition = true;
set hive.exec.dynamic.partition.mode = nonstrict;
-- Drop and recreate the destination table
DROP TABLE tweets;
CREATE EXTERNAL TABLE tweets
(
id BIGINT,
created_at STRING,
favorited BOOLEAN,
source STRING,
retweet_count INT,
retweeted_status STRUCT<
text:STRING,
user:STRUCT<screen_name:STRING,name:STRING>>,
entities STRUCT<
urls:ARRAY<STRUCT<expanded_url:STRING>>,
user_mentions:ARRAY<STRUCT<screen_name:STRING,name:STRING>>,
hashtags:ARRAY<STRUCT<text:STRING>>>,
text STRING,
user STRUCT<
screen_name:STRING,
name:STRING,
friends_count:INT,
followers_count:INT,
statuses_count:INT,
verified:BOOLEAN,
utc_offset:INT,
time_zone:STRING>,
in_reply_to_screen_name STRING
);
PARTITIONED BY (datehour INT)
ROW FORMAT SERDE 'com.cloudera.hive.serde.JSONSerDe'
LOCATION '/tmp/data_staging/tweets';
Save, quit and run the HiveQL script using the below command:
$ hive -f tweet.hql
This command runs the the tweet.hql file. Once the query completes, you get the prompt.
Let’s do a quick check, the following query returns a maximum of 10 tweets that contain the word Hive in the message text:
SELECT user.name, user.screen_name, count(1) as cc
FROM tweets
WHERE text like "%Hive%"
GROUP BY user.name, user.screen_name
ORDER BY cc DESC LIMIT 10;
Querying & Analyzing
Now that we have the data in HDFS and the table created in Hive, lets run some queries.
One of the way to determine who is the most influential person in a particular field is to to figure out whose tweets are re-tweeted the most. Give enough time for Flume to collect Tweets from Twitter to HDFS and then run the below query in Hive to determine the most influential person.
SELECT t.retweeted_screen_name, sum(retweets) AS total_retweets, count(*) AS tweet_count FROM (SELECT retweeted_status.user.screen_name as retweeted_screen_name, retweeted_status.text, max(retweet_count) as retweets FROM tweets GROUP BY retweeted_status.user.screen_name, retweeted_status.text) t GROUP BY t.retweeted_screen_name ORDER BY total_retweets DESC LIMIT 10;
Similarly to know which user has the most number of followers, the below query helps.
SELECT user.screen_name, user.followers_count c FROM tweets order BY c DESC;
Boom we have successfully summarized, queried and analyzed semi-structured data using Hive, let’s talk about more analysis in one of the coming blogs …
End notes
In this article we’ve discussed some of the benefits and trade-offs of using Hive, and seen how to build a SerDe to process JSON data, without any preparation of the data. By using the powerful SerDe interface with Hive, we can process data that has a looser structure than would be possible in a relational database. This enables us to query and analyze traditional structured data, as well as semi- and even unstructured data.